【Rust】Mutex 使用示例
使用 std::sync::Mutex 可以多线程共享可变数据,Mutex、RwLock 和原子类型,即使声明为 non-mut,这些类型也可以修改:
1 | use std::borrow::Cow; |
使用 std::sync::Mutex 可以多线程共享可变数据,Mutex、RwLock 和原子类型,即使声明为 non-mut,这些类型也可以修改:
1 | use std::borrow::Cow; |
Double Free使用 unsafe 特性构造指向同一块内存的两个变量,导致 Double Free:
1 | use std::{mem, ptr}; |
Rust 中使用 std::result::Result 表示可能出错的操作,成功的时候是 Ok(T),而出错的时候则是 Err(E):
1 | pub enum Result<T, E> { |
通常情况下,E 是实现 std::error::Error 的错误类型:
1 | pub trait Error: Debug + Display { |
我们通常也需要在自己的代码中自定义错误,并且为之手动实现 std::error::Error,这个工作很麻烦,所以就有了 thiserror,自动帮我们生成实现的 std::error::Error 的代码。
而借助于 anyhow::Error,和与之对应的 Result<T, anyhow::Error>,等价于 anyhow::Result<T>,我们可以使用 ? 在可能失败的函数中传播任何实现了 std::error::Error 的错误。
世界上的每个程序并非都是用 Rust 编写的,我们希望能够在我们的 Rust 程序中使用许多用其他语言实现的关键库和接口。Rust 的外部函数接口 (FFI) 允许 Rust 代码调用用 C 编写的函数,也可以是 C++。由于大多数操作系统都提供 C 接口,Rust 的外部函数接口允许立即访问各种低级功能。
在本章中,我们将编写一个与 libgit2 链接的程序,libgit2 是一个用于与 Git 版本控制系统一起工作的 C 库。首先,我们使用前一章中展示的 unsafe 特性展示直接从 Rust 使用 C 函数的例子,然后,我们将展示如何构建 libgit2 的安全接口,灵感来自开源 git2-rs。本文假设你熟悉 C 以及编译和链接 C 程序的机制,还假设熟悉 Git 版本控制系统。
现实中确实存在用于与许多其他语言进行通信的 Rust 包,包括 Python、JavaScript、Lua 和 Java。这里没有篇幅介绍它们,但归根结底,所有这些接口都是使用 C 外来函数接口构建的。
系统编程的秘密乐趣在于,在每一种安全语言和精心设计的抽象之下,都存在着极其 unsafe 的机器语言和小技巧,我们也可以用 Rust 来写。
到目前为止,我们介绍的语言可确保程序通过类型、生命周期、边界检查等完全自动地避免内存错误和数据竞争,但是这种自动推断有其局限性,有许多有价值的技术手段是无法被 Rust 认可的。
unsafe 代码告诉 Rust,程序选择使用它无法保证安全的特性。通过将代码块或函数标记为 unsafe,可以获得调用标准库中的 unsafe 函数、解引用 unsafe 指针以及调用用其他语言(如 C 和 C++ )编写的函数以及其他能力。
这种跳出安全 Rust 边界的能力使得在 Rust 中实现许多 Rust 最基本的功能成为可能,就像 C 和 C++ 用来实现自己的标准库一样。 unsafe 代码允许 Vec 有效地管理其缓冲区、 std::io 能直接和操作系统对话、以及提供并发原语的 std::thread 和 std::sync。
本节将 unsafe 功能的要点:
Rust 的 unsafe 块在安全的 Rust 代码和使用 unsafe 特性的代码之间建立了界限;
可以将函数标记为 unsafe,提醒调用者存他们必须遵守的额外规范以避免未定义的行为;
裸指针及其方法允许不受限制地访问内存,并允许构建 Rust 类型系统原本禁止的数据结构。尽管 Rust 的引用是安全但受约束的,但正如任何 C 或 C++ 程序员所知道的,裸指针是一个强大而锋利的工具;
了解未定义行为将帮助理解为什么它会产生比仅仅得到错误结果更严重的后果;
unsafe 的 Trait,类似于 unsafe 的函数,强加了每个实现必须遵循的规约;
Rust 语言支持宏,如我们之前使用的 assert_eq!,println! 等。宏做了函数不能做的一些事情,例如,assert_eq! 当一个断言失败时,assert_eq! 生成包含断言的文件名和行号的错误消息,普通函数无法获取这些信息,但宏可以,因为它们的工作方式完全不同。
宏是一种简写,在编译期间,在检查类型和生成任何机器代码之前,每个宏调用都会被扩展。也就是说,它被一些 Rust 代码替换。assert_eq! 调用扩展为大致如下:
1 | match (&gcd(6, 10), &2) { |
panic! 也是一个宏,它本身扩展为更多的 Rust 代码。该代码使用到了另外两个宏:file!() 和 line!()。 一旦 crate 中的每个宏调用都被完全展开,Rust 就会进入下一个编译阶段。
在运行时,断言失败看起来像这样:
thread 'main' panicked at 'assertion failed: `(left == right)`, (left: `17`, right: `2`)', gcd.rs:7
如果熟悉 C++,可能对宏有过一些不好的体验。但是 Rust 宏采用不同的方法,类似于 Scheme 的语法规则。与 C++ 宏相比,Rust 宏可以更好地与语言的其余部分集成,因此更不容易出错。宏调用总是标有感叹号 !,因此在阅读代码时它们会比较突出,所以不会意外调用它们。Rust 宏从不插入不匹配的括号或圆括号,并且 Rust 宏带有模式匹配,使得编写既可维护又易于使用的宏变得更加容易。
在本节中,我们将通过几个简单的例子来展示如何编写宏。但与 Rust 的大部分内容一样,理解宏需要下很大功夫。在这里将介绍一个很复杂的宏的设计,它可以将 JSON 文字直接嵌入到我们的程序中。但是宏的内容涵盖的非常多,因此这里将提供一些进一步研究的建议,包括我们在此处展示的高级技术,以及称为过程宏的更强大的工具。
如果我们正在开发一个聊天室,并且使用线程处理每个连接,我们的代码可能看起来像下面这个样子:
1 | use std::{net, thread}; |
对于每个新连接,这都会产生一个运行 serve 函数的新线程,该线程能够专注于管理单个连接的处理。
这很好用,但是如果突然用户达到成千上万时,线程堆栈增长到 100 KiB 或这更多时,这可能要花费几个GB的内存。线程对于在多个处理器之间分配工作是非常好的一种形式,但是它们的内存需求使得我们在使用时要非常小心。
不过可以使用 Rust 异步任务在单个线程或工作线程池上并发运行许多独立活动。异步任务类似于线程,但创建速度更快,并且内存开销比线程少一个数量级。在一个程序中同时运行数十万个异步任务是完全可行的。当然,应用程序可能仍会受到网络带宽、数据库速度、计算或工作固有内存要求等其他因素的限制,但内存开销远没有线程那么多。
一般来说,异步 Rust 代码看起来很像普通的多线程代码,除了涉及到的 I/O 操作,互斥锁等阻塞操作需要稍微的不同处理。之前代码的异步版本如下所示:
1 | use async_std::{net, task}; |
这使用 async_std 的net和task模块,并在可能阻塞的调用之后添加 .await。但整体结构与基于线程的版本相同。
本节的目标不仅是帮助编写异步代码,而且还以足够详细的方式展示它的工作原理,以便可以预测它在应用程序中的表现,并了解它最有价值的地方。
为了展示异步编程的机制,我们列出了涵盖所有核心概念的最小语言特性集:futures、异步函数、await 表达式、task 以及 block_on 和 spawn_local executor;
然后我们介绍异步代码块和 spawn executor。这些对于完成实际工作至关重要,但从概念上讲,它们只是我们刚刚提到的功能的变体。在此过程中,我们会可能会遇到一些异步编程特有的问题,但是需要学习如何处理它们;
为了展示所有这些部分的协同工作,我们浏览了聊天服务器和客户端的完整代码,前面的代码片段是其中的一部分;
为了说明原始 futures 和 executors 是如何工作的,我们提供了 spawn_blocking 和 block_on 的简单但功能性的实现;
最后,我们解释了 Pin 类型,它在异步接口中不时出现,以确保安全使用异步函数和 futures;
Rust 提供了一种非常好的并发使用方法,它不强制所有程序采用单一风格,而是通过安全地支持多种风格,并由编译器强制执行。我们将介绍三种使用 Rust 线程的方法:
Fork-join 并行;Chanel);在此过程中,将使用到目前为止所学的有关 Rust 语言的所有内容,Rust 对引用、可变性和生命周期的关注在单线程程序中足够有价值,但在并发编程中,这些规则的真正意义变得显而易见。
Fork-Join Parallelism最简单的用于多线程的案例是处理互不相干的任务,例如,我们要处理大量的文档,可能会这样写:
1 | fn process_files(filenames: Vec<String>) -> io::Result<()> { |
Rust 用于输入和输出的标准库功能围绕三个Trait组织:Read、BufRead 和 Write:
实现 Read 的值具有面向字节的输入的方法,他们被称为 Reader;
实现 BufRead 的值是缓冲读取器,它们支持 Read 的所有方法,以及读取文本行等的方法;
实现 Write 的值支持面向字节和UTF-8 文本输出,它们被称为 Writer;
在本节中,将解释如何使用这些Trait及其方法,涵盖图中所示的读取器和写入器类型,并展示与文件、终端和网络交互的其他方式。

Readers、WritersReaders 是内容输入源,可以从哪里读取字节。例如:
使用 std::fs::File::open 打开的文件;
可以从 std::net::TcpStream 代表的网络连接中读取数据;
可以从 std::io::stdin() 标准输入读取数据;
std::io::Cursor<&[u8]> 和 std::io::Cursor<Vec<u8>> 值,它们是从已经在内存中的字节数组或vector中“读取”的读取器;
Writers 是那些你可以把值写入的地方,例如:
使用 std::fs::File::create 创建的文件;
基于网络连接 std::net::TcpStream 传输数据;
std::io::stdout() 和 std::io:stderr() 可以用于向标准输出和标准错误写入内容;
std::io::Cursor<Vec<u8>> 类似,但允许读取和写入数据,并在vector中寻找不同的位置;
std::io::Cursor<&mut [u8]> 和上面的类似,但是不能增长内部的 buffer,因为它仅仅是已存在的字节数组的引用;
由于Reader和Writer有标准的 Trait(std::io::Read 和 std::io::Write),编写适用于各种输入或输出通道的通用代码是很常见的。 例如,这是一个将所有字节从任何读取器复制到任何写入器的函数:
1 | use std::io::{self, ErrorKind, Read, Write}; |
这是 Rust 标准库 std::io::copy() 的实现,因为它是泛型的,所以可以把数据从 File 复制到 TcpStream,或者从 Stdin 到内存中的 Vec<u8>。
Unicode 和 ASCII 匹配所有 ASCII 字符,从 0 到 0x7f。例如,都将字符 * 分配给码点 42。类似地,Unicode 将 0 到 0xff 分配给与 ISO/IEC 8859-1 字符集相同的字符,用于西欧语言的 8 位 ASCII 超集。Unicode 将此码点范围称为 Latin-1 代码块。
因为 Unicode 是 Latin-1 的超集,所以从 Latin-1 转换到 Unicode 是完全允许的:
1 | fn latin1_to_char(latin1: u8) -> char { |
假设码点在 Latin-1 范围内,反向转换也很简单:
1 | fn char_to_latin1(c: char) -> Option<u8> { |
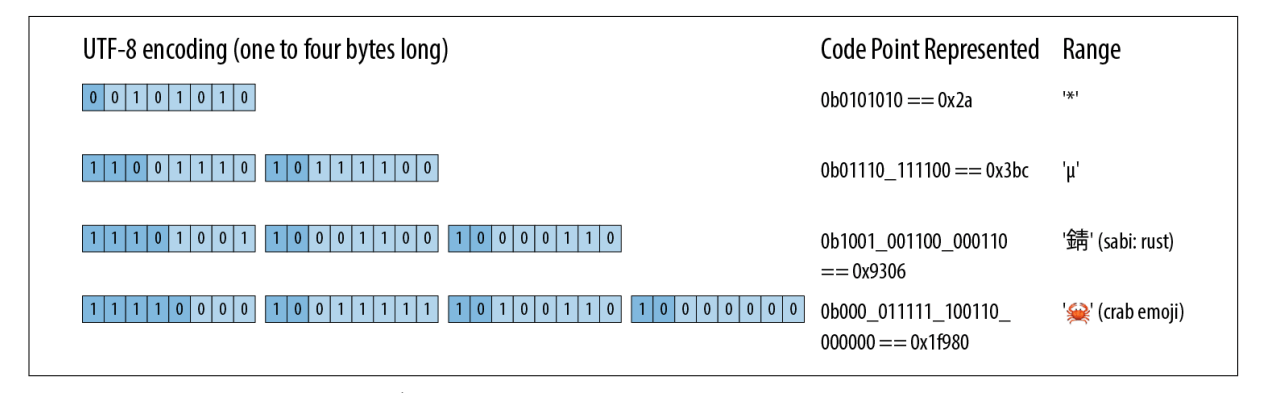
Rust 中 String 和 str 类型都是使用 UTF-8 编码格式,它是一种变长编码,使用1到4个字节对字符进行编码。有效的 UTF-8 序列有两个限制。首先,对于任何给定码点,只有最短的编码被认为是有效的,也就是不能花费4个字节来编码一个适合3个字节的码点。 此规则确保给定代码点只有一个 UTF-8 编码。其次,有效的 UTF-8 不得编码为 0xd800 到 0xdfff 或超过 0x10ffff 的数字:这些数字要么保留用于非字符目的,要么完全超出 Unicode 的范围。