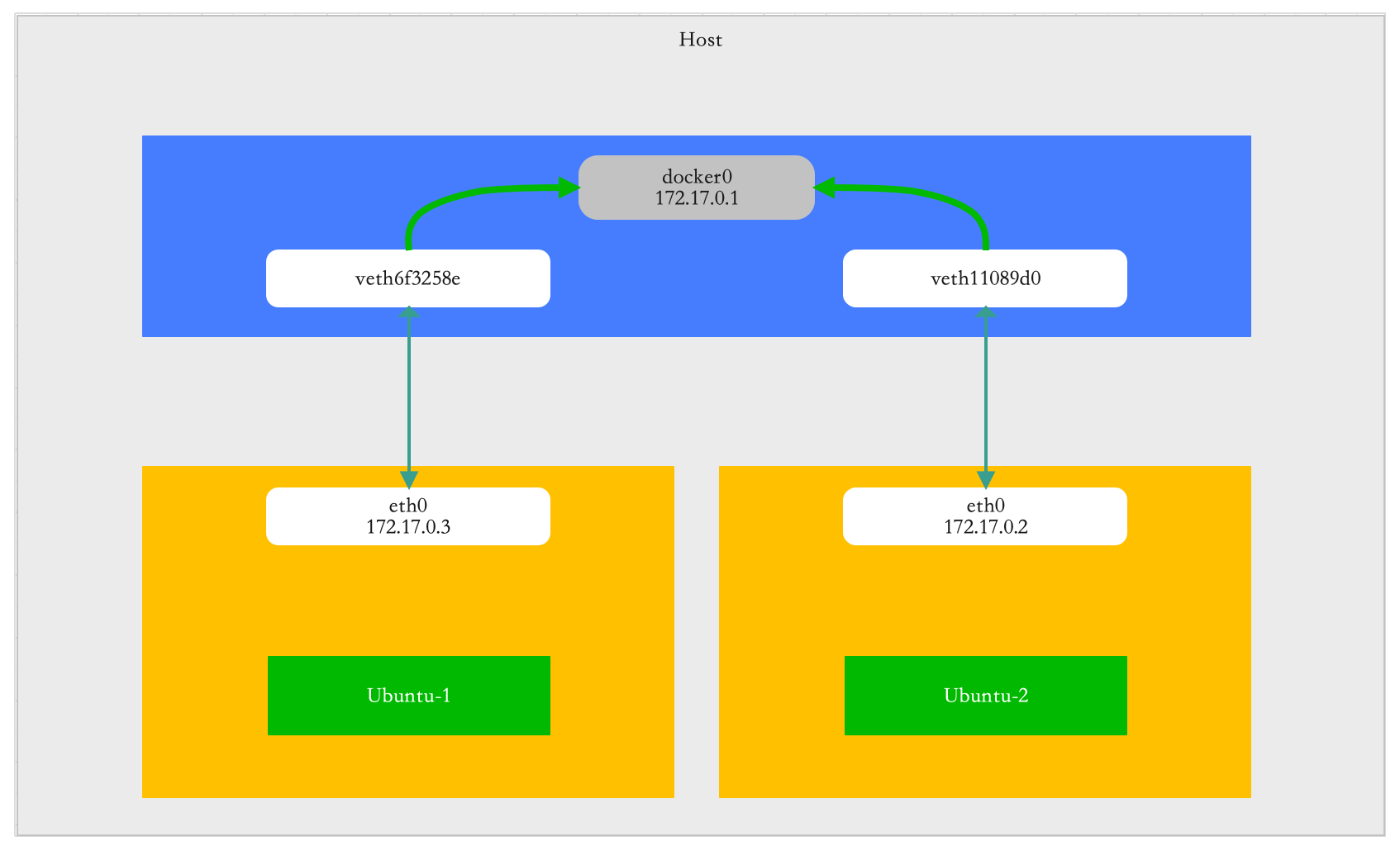
root@michael-host:/home/michael# ip addr show docker0 7: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ad:c7:75:98 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:adff:fec7:7598/64 scope link valid_lft forever preferred_lft forever root@michael-host:/home/michael#
root@679ef2c2dceb:/# ip addr show eth0 10791: eth0@if10792: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever root@679ef2c2dceb:/# root@679ef2c2dceb:/# ip route default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2 root@679ef2c2dceb:/#
1 2 3 4 5 6 7 8 9 10 11
root@8228a27f2052:/# root@8228a27f2052:/# ip addr show eth0 10793: eth0@if10794: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever root@8228a27f2052:/# root@8228a27f2052:/# ip route default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3 root@8228a27f2052:/#
root@ctrlnode:/home/michael# ip addr show type veth | grep 10792 10792: vethb2e6fb3@if10791: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default root@ctrlnode:/home/michael# root@ctrlnode:/home/michael# ip addr show type veth | grep 10794 10794: vethd08a547@if10793: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default root@ctrlnode:/home/michael# root@ctrlnode:/home/michael# ip addr show vethb2e6fb3 10792: vethb2e6fb3@if10791: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether fe:58:fc:10:a9:27 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::fc58:fcff:fe10:a927/64 scope link valid_lft forever preferred_lft forever root@ctrlnode:/home/michael# ip addr show vethd08a547 10794: vethd08a547@if10793: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether c6:3d:7c:33:5d:02 brd ff:ff:ff:ff:ff:ff link-netnsid 3 inet6 fe80::c43d:7cff:fe33:5d02/64 scope link valid_lft forever preferred_lft forever
怎么样证明他们插在了 docker0 网桥上呢?通过 brctl show 命令,Ubuntu 可以通过下面的命令进行安装:
apt install bridge-utils
brctl show 命令展示了插在 docker0 网桥上的设备,展示为 interface,表示一个端口:
1 2 3 4
root@michael-host:/home/michael/linux# brctl show bridge name bridge id STP enabled interfaces docker0 8000.0242adc77598 no vethb2e6fb3 vethd08a547
由于发送消息的目的 IP 和源 IP 在同一网络,所以消息都是通过二层网络直达目的主机,因此对于 ubuntu-1 容器来说,在它的网络协议栈中,就需要 eth0 网卡发送 ARP 广播,来通过 IP 地址找到目的IP对应的 MAC 地址,这个 ARP 请求最终会被 docker0 接收并且广播到插在这个网桥上其他设备,ubuntu-2 收到之后应答对应的 MAC 地址给 ubuntu-1 容器,有了这个 MAC 地址,ubuntu-1 就可以把数据发送出去。
# 创建一对 veth pair ip link add veth111 type veth peer name veth222
# 将 veth 两端分别加入两个命名空间 ip link set veth111 netns ns1 ip link set veth222 netns ns2
# 给两个 veth 设置ip 并且启用 ip netns exec ns1 ip addr add 10.1.1.2/24 dev veth111 ip netns exec ns2 ip addr add 10.1.1.3/24 dev veth222 ip netns exec ns1 ip link set veth111 up ip netns exec ns2 ip link set veth222 up
# ping 一下试试 root@michael-host:/home/michael/linux# ip netns exec ns1 ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.057 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.027 ms 64 bytes from 10.1.1.3: icmp_seq=3 ttl=64 time=0.035 ms ^C --- 10.1.1.3 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2115ms rtt min/avg/max/mdev = 0.027/0.039/0.057/0.012 ms root@michael-host:/home/michael/linux#
# 创建两对 veth ip link add veth1 type veth peer name vethpeer1 ip link add veth2 type veth peer name vethpeer2
# 启用 veth1 veth2 ip linkset veth1 up ip linkset veth2 up
# 将他们的对端分别加入到两个命名空间 ip linkset vethpeer1 netns net1 ip linkset vethpeer2 netns net2
# 启用这两个网络空间下的 lo 设备和 veth 的另一端 ip netns exec net1 ip linkset lo up ip netns exec net2 ip linkset lo up ip netns exec net1 ip linkset vethpeer1 up ip netns exec net2 ip linkset vethpeer2 up
# 给两个空间的 veth 设备设置ip地址 ip netns exec net1 ip addr add 10.100.0.10/16 dev vethpeer1 ip netns exec net2 ip addr add 10.100.0.20/16 dev vethpeer2
echo"" echo"" echo"[Debug] namespace: net1, vethpeer1:" ip netns exec net1 ip addr show vethpeer1
echo"" echo"[Debug] namespace: net2, vethpeer2:" ip netns exec net2 ip addr show vethpeer2
# 添加网桥设备并启用 ip link add br00 type bridge ip linkset br00 up
# 将 veth1 veth2 作为端口添加在网桥上 ip linkset veth1 master br00 ip linkset veth2 master br00
# 给网桥设置ip地址 ip addr add 10.100.0.1/16 dev br00
echo"" echo"" echo"[Debug] ip addr show br00:" ip addr show br00
# 给两个命名空间添加默认路由 ip netns exec net1 ip route add default via 10.100.0.1 ip netns exec net2 ip route add default via 10.100.0.1
# 显示两个命名空间路由信息 echo"" echo"" echo"[Debug] show default route for net1:" ip netns exec net1 route -n
echo"" echo"" echo"[Debug] show default route for net2:" ip netns exec net2 route -n
# 查看网桥设备信息 echo"" echo"" echo"[Debug] brctrl show:" brctl show
root@michael-host:/home/michael/linux# ./bridge.sh up ip_forward: /proc/sys/net/ipv4/ip_forward 1
[Debug] namespace: net1, vethpeer1: 551: vethpeer1@if552: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 32:4c:27:44:51:25 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.100.0.10/16 scope global vethpeer1 valid_lft forever preferred_lft forever inet6 fe80::304c:27ff:fe44:5125/64 scope link tentative valid_lft forever preferred_lft forever
[Debug] namespace: net2, vethpeer2: 553: vethpeer2@if554: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether b2:98:86:bb:f7:c9 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.100.0.20/16 scope global vethpeer2 valid_lft forever preferred_lft forever inet6 fe80::b098:86ff:febb:f7c9/64 scope link tentative valid_lft forever preferred_lft forever
[Debug] ip addr show br00: 555: br00: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 0a:63:b7:ef:ad:3d brd ff:ff:ff:ff:ff:ff inet 10.100.0.1/16 scope global br00 valid_lft forever preferred_lft forever inet6 fe80::4c56:d4ff:fe42:7b2/64 scope link tentative valid_lft forever preferred_lft forever
[Debug] show default route for net1: Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.100.0.1 0.0.0.0 UG 0 0 0 vethpeer1 10.100.0.0 0.0.0.0 255.255.0.0 U 0 0 0 vethpeer1
[Debug] show default route for net2: Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.100.0.1 0.0.0.0 UG 0 0 0 vethpeer2 10.100.0.0 0.0.0.0 255.255.0.0 U 0 0 0 vethpeer2
[Debug] brctrl show: bridge name bridge id STP enabled interfaces br00 8000.0a63b7efad3d no veth1 veth2
[Debug] ping: PING 10.100.0.20 (10.100.0.20) 56(84) bytes of data. 64 bytes from 10.100.0.20: icmp_seq=1 ttl=64 time=0.108 ms 64 bytes from 10.100.0.20: icmp_seq=2 ttl=64 time=0.038 ms
--- 10.100.0.20 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1009ms rtt min/avg/max/mdev = 0.038/0.073/0.108/0.035 ms PING 10.100.0.10 (10.100.0.10) 56(84) bytes of data. 64 bytes from 10.100.0.10: icmp_seq=1 ttl=64 time=0.057 ms 64 bytes from 10.100.0.10: icmp_seq=2 ttl=64 time=0.065 ms
--- 10.100.0.10 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1021ms rtt min/avg/max/mdev = 0.057/0.061/0.065/0.004 ms